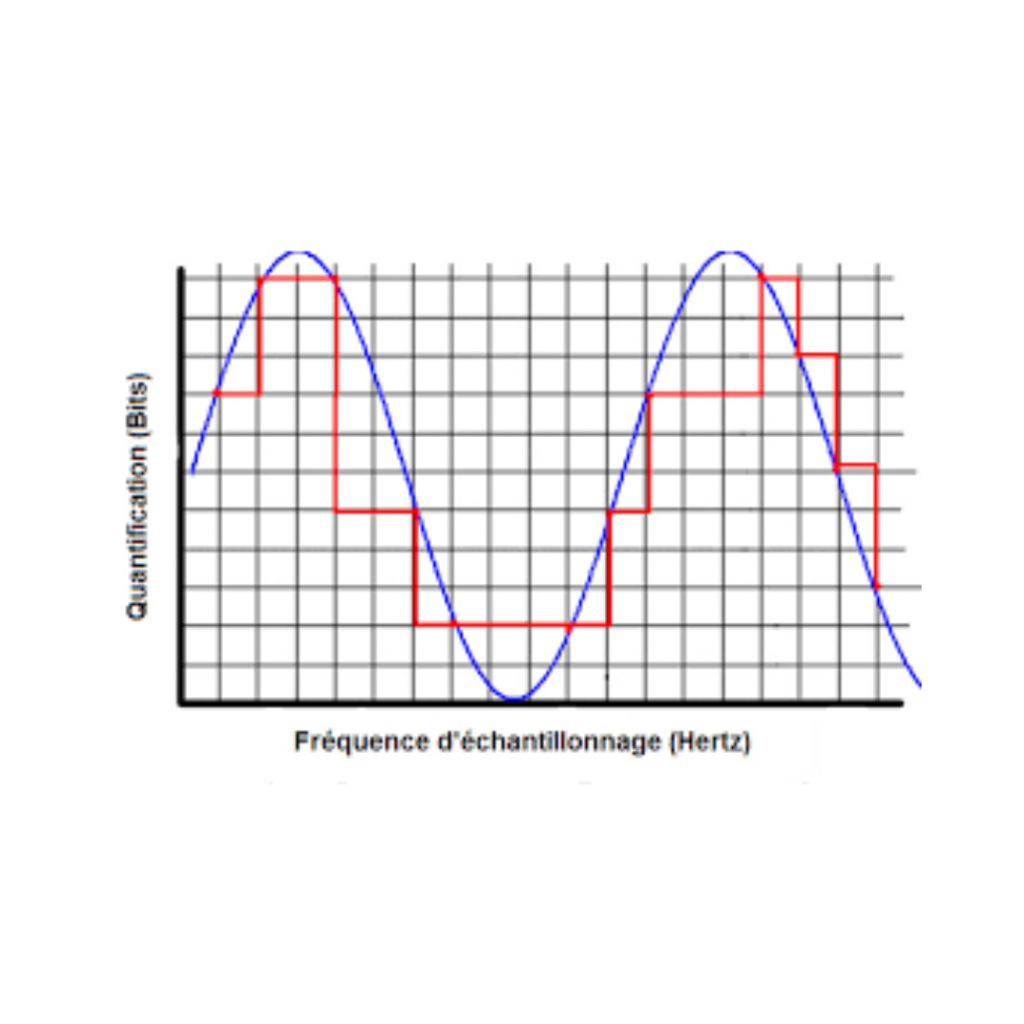
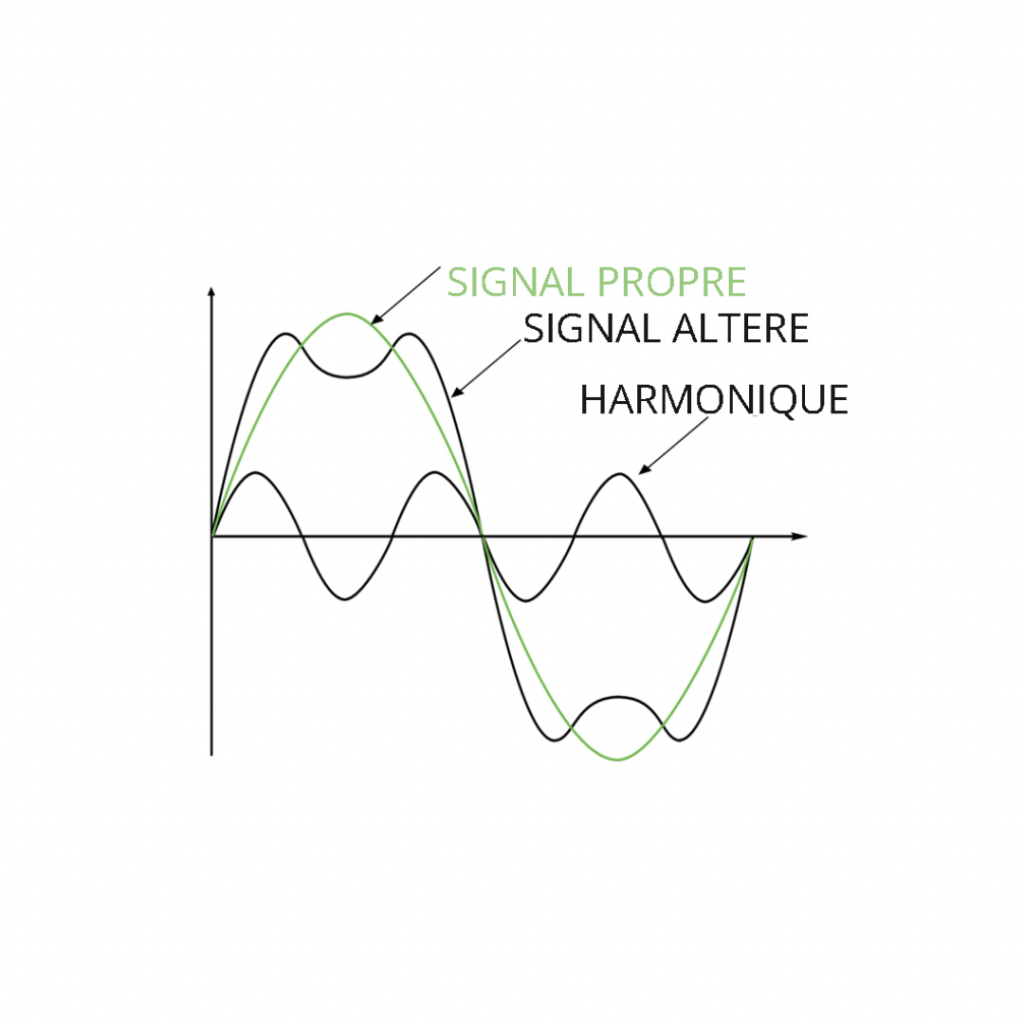
Formats audio numériques Définition rapide : L’industrie de l’enregistrement de musique produit les données audio numériques au format PCM (ou rarement DSD). Ces données PCM sont portées sur des disques optiques (CD, DVD, Blu-ray et SACD si DSD). Pour la musique dématérialisée, ces données PCM sont encapsulées dans des fichiers informatiques conteneurs. Ils peuvent être non compressés (WAVE ou AIFF) ou compressés sans perte « lossless » (FLAC, ALAC) ou compressés avec pertes d’informations « lossy » (MP3, MQA, AAC, WMA…). Détails : À la sortie du studio, le format des données du master est encodé en PCM avec une résolution de 24 bits (voire 32 bits) et une fréquence d’échantillonnage de 96 kHz (voire 192 kHz). Très rarement, le format des données est encodé en DSD avec une résolution d’un seul bit et une fréquence d’échantillonnage de 2,8 MHz, 5,6 ou 11,2 MHz (cela concerne environ un millier d’albums). Plus la résolution et la fréquence d’échantillonnage sont élevées et plus le volume de données et la puissance de traitement sont importants. Ces données audio numériques sont livrées sur des disques ou des fichiers informatiques avec ou sans compression. Les disques optiques. Le CD classique. Il est considéré comme le format PCM de qualité standard. Nécessite un lecteur CD. Résolution de 16 bits et fréquence d’échantillonnage de 44,1 kHz. Le débit des échantillons PCM est : 2 canaux x 16 bits x 44 100 Hz = 1 411 200 bits par seconde ou 1 411 kb/s. Mono et stéréo. Les CD dont la résolution a été étendue à 20 bits, 24 bits voire 32 bits. Nécessite un lecteur CD. Ce sont les CD K2, K2HD, XRCD, XRCD2, XRCD24, UHD dont la qualité audio est reconnue et recherchée par les audiophiles. Le DVD audio. Nécessite un lecteur DVD. Résolution de 16 bits et fréquence d’échantillonnage de 48 kHz. Débit stéréo ; 1 536 kb/s. Mono, stéréo et multicanaux. Le Blu-ray audio. Nécessite un lecteur Blu-ray. Résolution de 24 bits et fréquence d’échantillonnage de 96 kHz. Il est certifié Hi-Res. Débit stéréo : 4 608 kb/s. Mono, stéréo et multicanaux. Le SACD. Nécessite un lecteur SACD. Résolution de 1 bit et fréquence d’échantillonnage de 2,8 MHz, 5,6 ou 11,2 MHz. Mono, stéréo et multicanaux. Le SACD hybride, en plus du format DSD, contient les données PCM du CD classique pouvant être lu par un lecteur CD. Les fichiers informatiques conteneurs. Quand les fichiers de données PCM sont pris en charge directement sur un ordinateur, elles sont encapsulées dans un fichier conteneur. Il y a un ajout de blocs de données définissant la représentation des données PCM, les informations du codage et du décodage (le codec) et de métadonnées (pochette de l’album par ex.). Non compressés, les fichiers conteneurs sont au format WAVE sur Windows et AIFF sur OS X. WAVE (WAVEform ou forme de la vague). Résolution de 16 à 24 bits et fréquence d’échantillonnage de 44,1 à 192 kHz. Mono, stéréo et multicanaux. AIFF (Audio Interchange File Format ou format de fichier pour l’échange audio). Résolution de 16 à 24 bits et fréquence d’échantillonnage de 44,1 à 192 kHz. Mono, stéréo et multicanaux. Le volume des données de ces fichiers peut être très conséquent. Il augmente fortement avec la qualité et peut représenter plusieurs Go pour un album. Afin de limiter l’espace utilisé, des algorithmes de compression sont utilisés dans différents codecs pour créer des formats de fichiers audio conteneurs moins volumineux. Les formats de compression sans perte (lossless) compressent les données lors de leur codage et restituent le signal audio numérique d’origine lors du décodage. FLAC (Free Lossless Audio Codec ou codec audio sans perte libre). Ce format cumule les avantages d’être libre et de compresser les données audio PCM dans tous les niveaux de qualité sans altérer le signal d’origine. Ses atouts l’ont conduit à devenir le codec de prédilection des mélomanes audiophiles. C’est également le format utilisé pour la diffusion de musique en ligne en qualité CD et Hi-Res des plateformes de streaming. Résolution de 16 à 32 bits et fréquence d’échantillonnage de 44,1 à 655 kHz. Mono, stéréo et multicanaux. ALAC (Apple Lossless Audio Codec ou codec audio sans perte d’Apple). C’est la version Apple du codec lossless destiné aux appareils et logiciels de la marque. Apple a toutefois publié son code source en 2011. Il est évidemment utilisé pour la diffusion de la musique en qualité CD ou Hi-Res de son service de musique en ligne en 2021. Résolution de 16 à 32 bits et fréquence d’échantillonnage de 44,1 à 384 kHz. Mono, stéréo et multicanaux. Avant l’avènement de ces codecs sans perte, permis grâce à l’extension des espaces de stockage et des débits des matériels et d’internet, les formats des codecs nécessitent une compression plus importante. Pour y parvenir, ces codecs sacrifient des informations audio des données PCM et en particulier les hautes fréquences, les harmoniques des autres fréquences et la dynamique. Ces codages sont irréversibles, les informations supprimées sont définitivement perdues. Ce sont les codecs avec pertes d’information (lossy). MP3 (MPEG-1/2 Audio Layer 3). Émanation du codec vidéo MPEG, ce codec est encore largement utilisé. Résolution de 16 bits et fréquence d’échantillonnage de 44,1 kHz. Débit maximum de 320 kb/s (pour rappel, le CD est a 1411 kb/s). Mono et stéréo. AAC (Advanced Audio Codec ou codec audio avancé). Ce codec dérive du MPEG-4 (MP4) et est surtout utilisé par Apple et Dolby Digital. C’est également l’un des codecs le plus utilisé pour la liaison Bluetooth. Débits usuels : 256 ou 320 kb/s. Débit maximum de 500 kb/s pour le xHE-AAC. Mono, stéréo et multicanaux. WMA (Windows Media Audio). Lancé par Microsoft en 1999 pour concurrencer le MP3, il est moins destructif que ce dernier. Résolution de 16 bits à 24 bits et fréquence d’échantillonnage de 44,1 kHz à 96 kHz. Débit maximum de 768 kb/s. Mono, stéréo et multicanaux. MQA (Master Quality Authenticated ou qualité « master » authentifiée) Lancé en 2014 par la société anglaise Meridian Audio, ce codec crée des fichiers, à partir des masters de studio en 24 bits et 96 ou 192 kHz, dont la résolution est ramenée à 17 bits et la fréquence d’échantillonnage à 48 kHz. Mais, il y a une hybridation de compression sans perte (lossless) et de compression avec pertes (lossy). En effet, les 13 premiers bits sont compressés sans perte et les 4 derniers avec pertes. Et, il